新闻>>你的位置:开云体育登录入口kaiyun官网首页 > 新闻 > 欧洲杯体育即系统性修改模子结构-开云体育登录入口kaiyun官网首页
欧洲杯体育即系统性修改模子结构-开云体育登录入口kaiyun官网首页
发布日期:2025-11-10 08:28 点击次数:78

(起原:机器之心)
扩散话语模子(Diffusion Language Models,DLM)一直以来都令究诘者颇感酷爱酷爱,因为与必须按从左到右王法生成的自转头模子(Autoregressive, AR)不同,DLM 能罢了并行生成,这在表面上不错罢了更快的生成速率,也能让模子基于前后文更好地默契生谚语境。
有关词,尽管后来劲苍劲,DLM 的检会仍然充满挑战,主要原因是它在 scaling 上的服从相对低于 AR 模子。举例,径直检会 DLM 需要在有限的数据集上进行更屡次迭代,才能卓绝径直检会的 AR 模子。此外,AR 模子还领有显耀的「先发上风」—— 包括老练的检会基础神情、踏实的检会配方以及庸俗的从业者警戒累积。
为了克服这些难点,来自 Radical Numerics(一个新的 AI 初创)的究诘团队遴荐了另一条路:在现存自转头模子的基础上进行校正,让它具备扩散话语模子的才气。

他们刚刚发布的 RND1-Base(Radical Numerics Diffusion)是迄今为止限制最大的开源扩散话语模子。其生成效果如下:
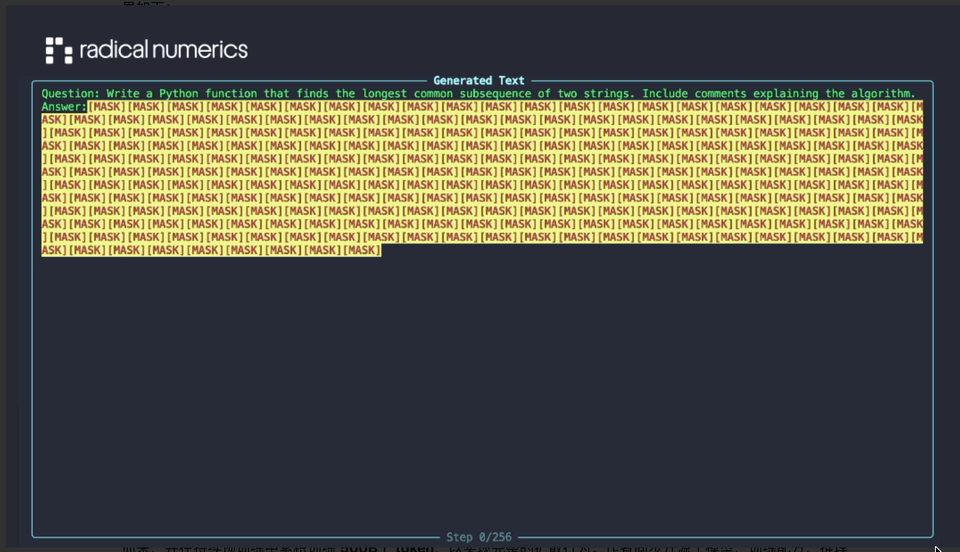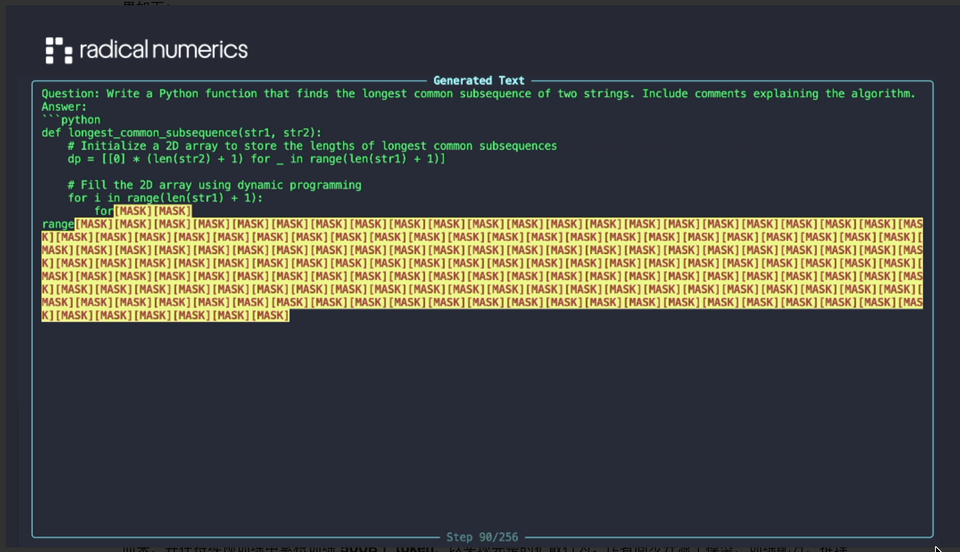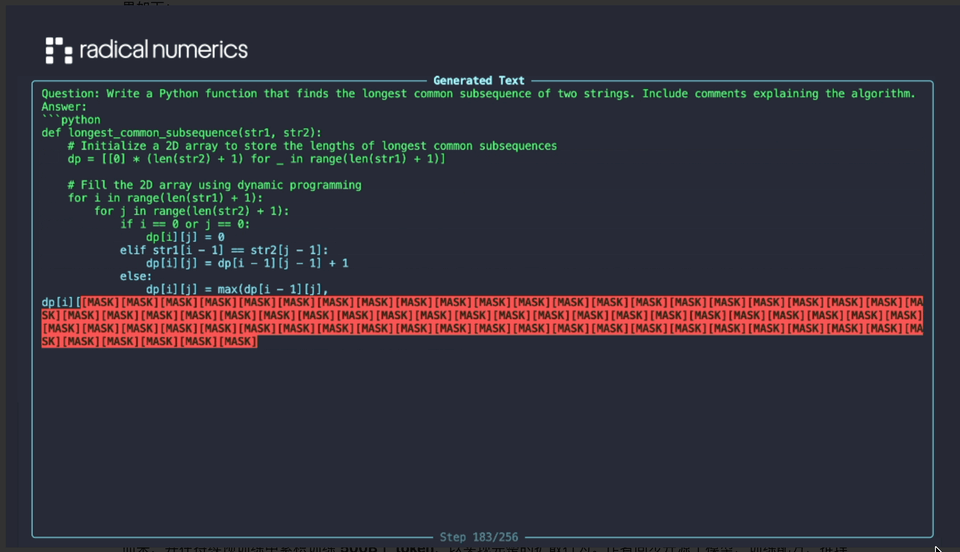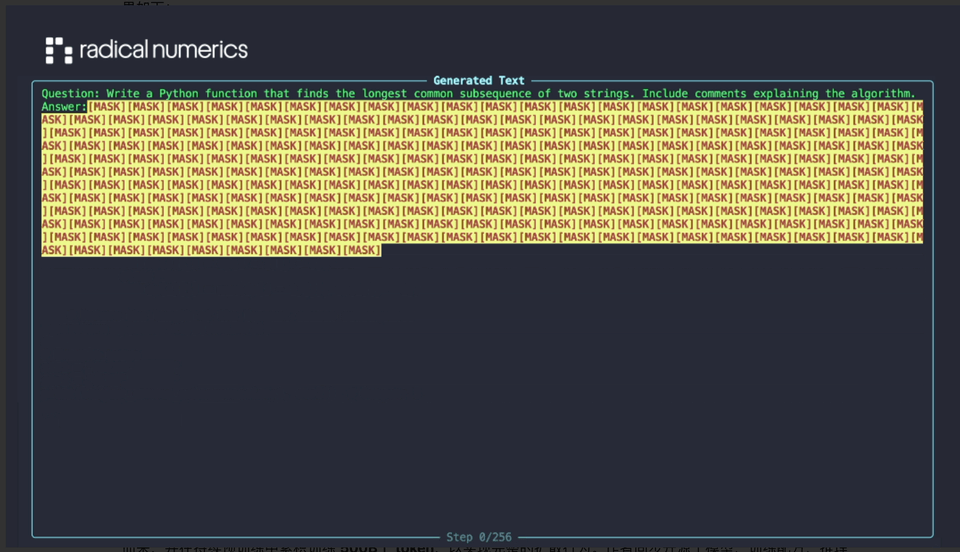
这是一个本质性的 30B 参数稀少 MoE 模子,其中有 3B 激活参数,由一个预检会的 AR 模子(Qwen3-30BA3B)鼎新而来,并在握续预检会中累积检会 500B 个 token,以罢了齐全的扩散步履。作家同步开源了模子、检会配方、推理代码以及样例输出。

技艺论说:Training Diffusion Language Models at Scale using Autoregressive Models论说连气儿:https://www.radicalnumerics.ai/assets/rnd1_report.pdf代码连气儿:https://github.com/RadicalNumerics/RND1HuggingFace 连气儿:https://huggingface.co/radicalnumerics/RND1-Base-0910
这项究诘的主要孝敬包括:
系统性究诘了大限制 A2D(Autoregressive-to-Diffusion)鼎新过程中的要津要素,如动手化政策、层级学习率和临界批大小。识别出大要罢了可扩张性与踏实性的要津要素,并证据当这些要素与老练的自转头预检会样子纠合时,绵薄的技艺组合也能催生可扩张的 DLM。推出了迄今为止最大的基础扩散话语模子 RND1-30B,展示了将自转头预检会警戒科学化鼎新后可在多项基准测试中取得超卓证据。
具体来说,究诘者在推理(MMLU、ARC-C、RACE、BBH)、STEM(GSM8K)以及代码生成(MBPP)等通用基准测试中测试了 RND1。适度泄漏,它在通盘评测中均踏实卓绝现存 Dream-7B 和 LLaDA-8B,同期保握了其自转头基础模子的苍劲性能。

这些适度标明,将扩散话语模子限制扩张到 80 亿参数以上不仅可行,并且切实灵验。A2D 鼎新可能是检会 DLM 更优的政策。RND1 亦然首个在此限制上奏效展示扩散模子检会的开源神气。
不外,需要指出的是,究诘者并未将 RND1 与 Llada 系列的最新模子 ——LLaDA-MoE-7B-A1B 进行对比。从部分主义来看,RND1 并未卓绝 LLaDA-MoE-7B-A1B 的证据。两个模子哪个更强还需要进一步 PK。

绵薄握续预检会(SCP)
从一个自转头查验点检会扩散话语模子,会引出两个中枢问题:
第一,如安在一个蓝本仅扶持因果闪耀力(causal attention)的架构中引入双向高下文?
第二,如安在鼎新过程中保留 AR 模子从数万亿 token 预检会中赢得的话语与事实学问?
早期究诘提议了多阶段复杂经过,举例闪耀力掩码退火(attention mask annealing),通过慢慢舒缓因果掩码罢了双向闪耀力;或嫁接法(grafting),即系统性修改模子结构,用双向闪耀力替换因果闪耀力。
这些样子在小限制模子上灵验,但经常引入稀奇缱绻遴荐(如掩码变化政策、退火 / 嫁接诊治),难以踏实地扩充至大限制。
相较之下,作家发现了一种更绵薄的样子 —— 绵薄握续预检会(SCP),大要达到与这些复杂 A2D 鼎新经过格外的性能。
其配方极为径直:
从一个苍劲的 AR 查验点动手;在动手化时将因果掩码替换为双向掩码;在掩码扩散场地下连续预检会,并领受学习率预热。
通过层级学习率保留 AR 预检会学问
A2D 鼎新濒临的主要风险之一是可怜性渐忘:模子可能在鼎新过程中丢失原有的事实学问。 既有究诘标明,Transformer 类话语模子中的学问(尤其是事实有关)主要编码在 FFN/MLP 层中 。基于这一意志,他们在不同参数组间领受了分层学习率政策:
在鼎新时刻,闪耀力层使用更高的学习率以便快速允洽双向高下文,而非闪耀力层(如 MLP 与镶嵌层)使用较低学习率,以最猛进度保留 AR 预检会学问。
A2D 鼎新在大 batch size 检会下证据更佳
自转头检会与扩散检会的一个轻飘但要津的差别在于:每个批次提供的监督信号量不同。 在 AR 模子中,每个 token 都会参与亏本接头;而在扩散检会中,只须序列中被隐敝的位置会参与监督。在次第掩码扩散场地下,平均掩码比例约为 50%,也等于说只须一半的 token 参与学习。 这种较弱的学习信号意味着,用于 scale batch size 和学习率的次第自转头启发式样子不一定适用于扩散检会。
为更好默契这少许,作家计算了临界批大小(Critical Batch Size, CBS)—— 即当数据并行度连续增大时,亏本创新收益动手递减的阈值。按照其他论文中的样子,他们通过分支检会本质来实证详情该点。
从一个在 SCP 配方下已检会 600 亿 token 的 40 亿参数模子查验点起程,作家启动了四个仅在全局批量大小上不同的并行检会分支。他们诊治学习率、保握优化器栽培与权重衰减不变,并在 token 空间上对王人预热与衰减诊治。每个分支再检会稀奇 50 亿 token。
本质适度标明,在 40 亿参数限制下,跟着批量增大,扩散亏本握续单调下落,直到约 800 万 token 仍有收益。换句话说,扩散话语模子在握续预检会阶段大要灵验愚弄更大的 batch size—— 这对大限制检会是一个积极信号。

为什么要校正自转头模子?
RND1 展示了如安在不推倒重来的情况下,高效探索新架构与新检会范式。
这种服从体现了 Radical Numerics 中枢扉念的本色 —— 构建一个大要递归自我创新的自动化 AI 究诘平台,让 AI 系统匡助缱绻和优化下一代 AI。
通过自动化本质轮回,他们大要更快地遍历搜索空间,考证更斗胆的念念法。RND1 恰是这一理念的首个具体适度之一。

Radical Numerics 的首创成员来自 DeepMind、Meta、Liquid、Stanford 等顶级机构,偏好搀杂架构、Hyena 和 Evo 等技艺。在一个酬酢媒体帖子中,公司首创东谈主之一 Michael Poli 弘扬了他们的信念和愿景。

感酷爱酷爱的读者不错查阅更多贵府了解该公司。
参考连气儿:https://www.radicalnumerics.ai/blog/rnd1欧洲杯体育
